
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다." 참고해서 리뷰 봐주시면 되겠습니다.^^
http://www.yes24.com/Product/Goods/115633781
트랜스포머를 활용한 자연어 처리 - YES24
자연어를 찰떡같이 알아듣는 트랜스포머 완벽 해부하기 트랜스포머는 우리 주변에 가득하다! 트랜스포머 아키텍처는 순식간에 자연어 처리 분야를 지배했다. 기자처럼 뉴스를 작성하고, 프로
www.yes24.com
트랜스 포머를 활용한 자연어 처리
(Natural Language Processing with Transformer)
1. 대상 독자
파이썬 프로그래밍에 능숙하고 딥러닝 프레임워크, 파이토지 or 텐서플로우의 기본을 알고 있는 사람
모델을 GPU에서 훈련한 경험도 있는 사람
2. 책의 구성
책의 목차 구성을 보면 실질적으로 기본적인 개념을 이해한 후, 아키텍처를 이해하고, 자연어 처리를 하는 스텝 바이 스텝 형식으로 내용을 풀어가고 있으며 소스코드도 제공이 된다.
자연어 처리, 특히 요즘 가장 핫한 GPT에 대해 이해하고자 하는 사람들에게는 많은 도움이 되는 책이 아닐까 싶다.
트랜스포머 이해 -> 허깅스페이스 생태계 -> 트랜포머 아키텍처 설명 -> 다국어 텍스트 처리 -> 텍스트 요약 -> 리뷰 기반 질문 답변 시스템 -> 모델 성능 -> 레이블링된 데이터 없을때 처리 -> 파이썬 소스 코드 자동 완성하는 모델 밑바닥부터 만들기 -> 트랜스포머 모델의 전망과 분야
[목차]
1장 트랜스포머 소개, 용어, 이해, 허깅스페이스 생태계
2장 감성 분석 작업에 초점을 두고 Trailer API 소개
3장 트랜스포머 아키텍처를 자세히 설명
4장 다국어 텍스트에서 개체명을 인식하는 작업에 초점
5장 텍스트를 생성하는 트랜스포머 모델의 능력을 탐구하고 디코딩 전략과 측정 지표를 소개
6장 텍스트 요약 : sequence to sequence 작업을 살펴보고 이 작업에 사용하는 측정 지표를 알아본다.
7장 리뷰 기반 질문 답변 시스템을 만드는 데 초점을 두고 헤이스택을 사용한 검색 방법을 안내한다.
8장 모델 성능에 초점을 맞춘다.(시퀀스 분류 문제의 일종인) 의도 감지 작업을 알아보고 지식 정제, 양자화, 가지치기 같은 기술을 탐색한다.
9장 레이블링된 대량의 데이터가 없을 때 모델 성능을 향상할 방법을 알아본다. 깃허브 이슈 태거를 만들고 제로샷 분류와 데이터 증식 같은 기술도 살펴봅니다.
10장 파이썬 소스 코드를 자동 완성하는 모델을 밑바닥부터 만들고 훈련하는 방법을 알려줍니다. 데이터셋 스트리밍과 대규모 훈련에 대해 배우고 사용자 정의 토크나이저도 만듭니다.
11장 트랜스포머 모델의 도전 과제와 흥미로운 신생 연구 분야를 소개합니다.
3. 예제 실습
실습 도구
- 구글 코랩
- 캐글 노트북
- 페이퍼스페이스 그레디언트 노트북
예제를 실행하기 위한 깃허브 저장소
- https://github.com/rickiepark/nlp-with-transformers
참고
- 16G 메모리의 NVIDIA Tesla P100 GPU를 사용했음
- 일부 무료 플랫폼에서 제공하는 GPU는 메모리가 작으므로 모델을 훈련할 때 배치 크기를 줄여야 함.
4. 트랜스포머
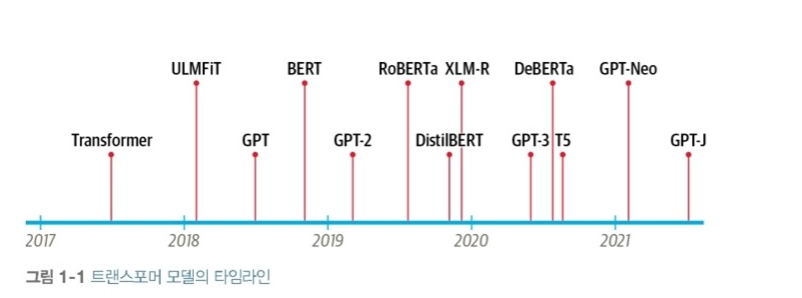
구글의 연구원들이 2017년 논문에서 시퀀스 모델링을 위한 새로운 신경망 아키텍처인 ‘트랜스포머’를 제안했음
이 ‘트랜스포머’ 아키텍처는 기계 번역 작업의 품질과 훈련 비용 면에서 순환 신경망(RNN)을 능가했음
이 ‘트랜스포머’ 아키텍처는 현재 가장 유명한 GPT와 BERT를 만드는 데 많은 영향을 끼쳤다.
GPT와 BERT는 트랜스포머 아키텍처와 비지도 학습을 결합해 어떤 작업에 특화된 모델을 만들때 밑바닥 부터 훈련하지 않더라도 거의 모든 NLP 벤치마크에서 매우 좋은 점수를 받았다.
‘트랜스포머' 모델이 만들어진 순서를 확인해보면 아래와 같다. 현재는 GPT-4가 나온 상태
5. 트랜스포머 아키텍처의 새로운 점 3가지
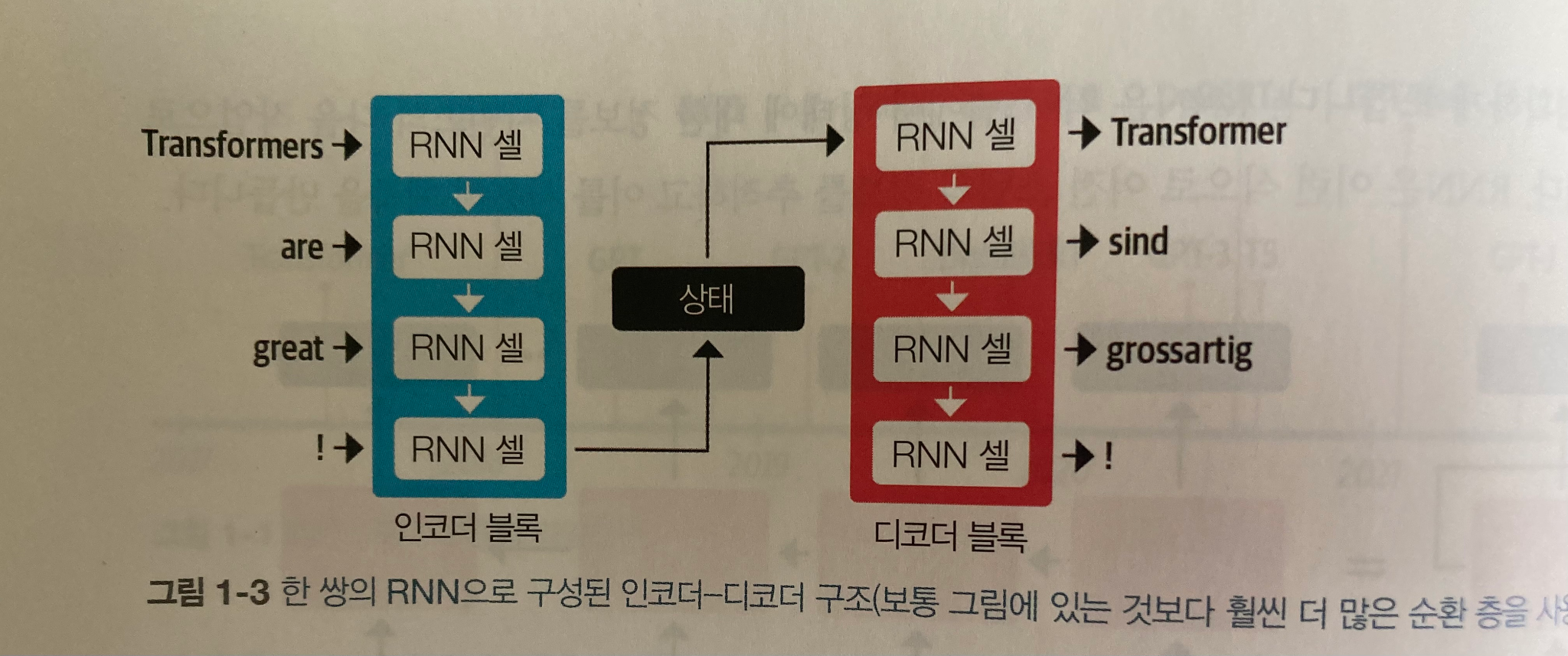
5-1. 인코더-디코더 프레임워크
영어를 독일어로 바꿀때 인코더 블록과 디코더 블록에서 아래와 같이 처리를 해준다.
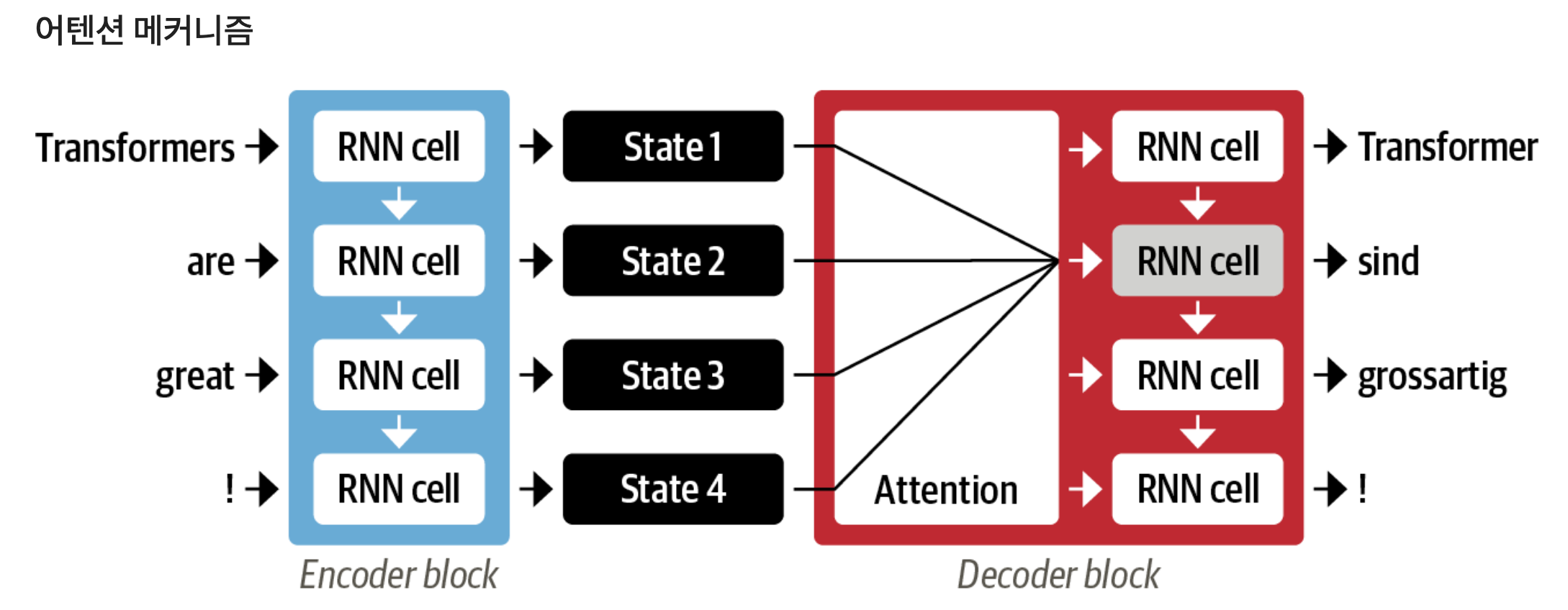
5-2. 어텐션 메커니즘
위에서 인코더 블록에서 처리하고 난 후에 디코더 블럭에서 인코더 블록에서 처리된 모든 상태를 처리하게되면 디코더에 한꺼번에 많은 입력이 발생하기 때문에 이를 어떻게 온 상태를 먼저 처리를 할지를 선택하는 것이 필요한데, 그 우선순위를 정해주는 것이 ‘어텐션 메커니즘’이다.
5-3. 전이 학습
합성곱 신경망 하나의 작업에서 진행한 후 다음 학습에 기존에 학습한 내용의 가중치를 적용해서 학습하는 형태, 비전 학습에서 많이 사용함.

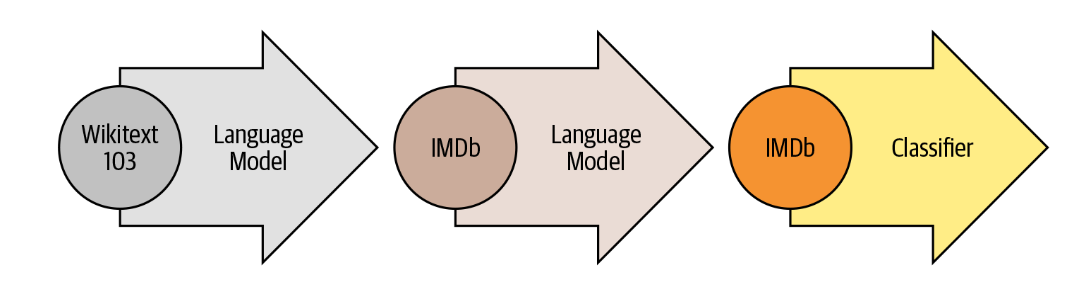
5-4. 전이학습 방법
> 사전훈련 - 언어 모델링 : 이전 단어를 바탕으로 다음 단어를 예측하는 방법
> 도메인 적응 : 언어 모델을 대규모 말뭉치에서 사전 훈련한 후, 도메인 내 말뭉치에 적응시킨다. (아래 그림 참고)
> 미세 튜닝 : 도메인 적응 단계에서 언어 모델을 타깃 작업을 위한 분류 층과 함께 미세 튜닝을 한다. (아래 그림 참고)
5-5. NLP에서 셀프 어텐션과 전이 학습을 결합한 모델 릴리즈
> GPT : 트랜스포머의 아키텍처 중 디코더 부문만 사용하고 ULMFiT 같은 언어 모델링 방법을 사용한다.
> BERT : 트랜스포머 아키텍처 중 인코더 부분을 사용하고 ‘마스크드 언어 모델링(masked language modeling)’이라는 특별한 형태의 언어 모델링을 사용
책을 리뷰하면서 내용을 살펴보니까 자연어 처리의 최신버전의 기본적인 동작방법과 모델을 발전시켜 나가는 방법에 대해
궁금하신 분들은 보시면 도움이 될 것 같습니다. 요즘 가장 핫한 GPT를 이해하는데도 도움이 되지 않을까 싶습니다.
무엇이든 그냥 막 사용하는 것 보다는 원리를 이해하고 사용하면 더 잘사용할 수 있지 않을까 생각이 됩니다.
자연어처리의 원리를 이해해 보시고, 이를 바탕으로 ChatGPT같은 도구를 적절하게 사용해서 생산성 향상을 시키면 좋지 않나 싶습니다. 읽어주셔서 감사합니다. ^^



